類神經網路中神經元對特定單字的預測

本文譯自 We Found An Neuron in GPT-2 ,作者 Clement Neo 是一位倫敦的大學生。這篇文章源自他在黑客松中的題目延伸,2月的時候就在hackernews看到這篇文章,看完覺得這太好玩了,趁現在期中考結束試著再讀一次順便翻譯看看,有些用詞目前沒有公認的中文,所以看起來可能會有些彆扭,我會盡量在這些單字後加上原文,這篇文章涉及如何找尋 LLM 處理特定 token 時所涉及的神經元,畢竟現在類神經網路最為人詬病的就是就像個黑盒子一樣,沒有人知道中間是如何運作的,所以這篇文章也可以說是試圖去解釋類大型語言模型的運作方式!
2023/05/10 更新: OpenAI最近也幹了類似的事,他們用 GPT-4 去標記 GPT-2 輸出時每個神經元對不同文字的輸出影響,試圖解釋 GPT-2 的運作方式
OpenAI 用GPT-4 來理解 GPT-2 是什麼
我們在 GPT-2 中找到了”an”神經元
作者:Joseph Miller、Clement Neo
這個研究始於一個問題:GPT-2 是如何知道何時該使用 “an” 而不是 “a” ?以人類來說,這個選擇取決於後面的單詞是否以母音為開頭,但 GPT-2 一次只能輸出一個單詞(準確來說,1個 token),他是如何判斷的?
雖然我們還沒有完整的答案,但我們確實在 GPT-2 Large 模型中找到了一個對於 gpt 預測 “ an” 這個 token 至關重要的單個 MLP 神經元。同時,我們也發現這個神經元的權重與 “ an” token 的嵌入相對應,這讓我們能夠以相同方法找到其他也能預測特定 token 的神經元。
發現神經元
選擇提示詞(prompt)
想出一個能讓 GPT-2 輸出 “ an”(前面的空格是token的一部分)作為最佳預測的提示(prompt)是非常困難。我們實驗後最後放棄了 GPT-2_small 模型,轉向 GPT-2_large。稍後我們將會看到,即使是 GPT-2_large 也會系統性地低估 “ an” 這個 token。這可能是因為較小的語言模型依賴於 “ a” 的頻率更高,更有可能做出最佳猜測。我們最終找到的能讓 “ an” 的機率達到 64% 的提示是:
“I climbed up the pear tree and picked a pear. I climbed up the
appletree and picked”
第一句是必要的,因為它可以讓模型朝著不定冠詞的預測方向前進,如果沒有第一句,模型會做出其他預測,例如: “[picked] up”
在繼續之前,讓我們快速回顧一下 Transformer 架構 。每個注意力區塊和 MLP 都會將輸入加到殘差流(residual stream)中。

Logit 透鏡(Logit Lens)
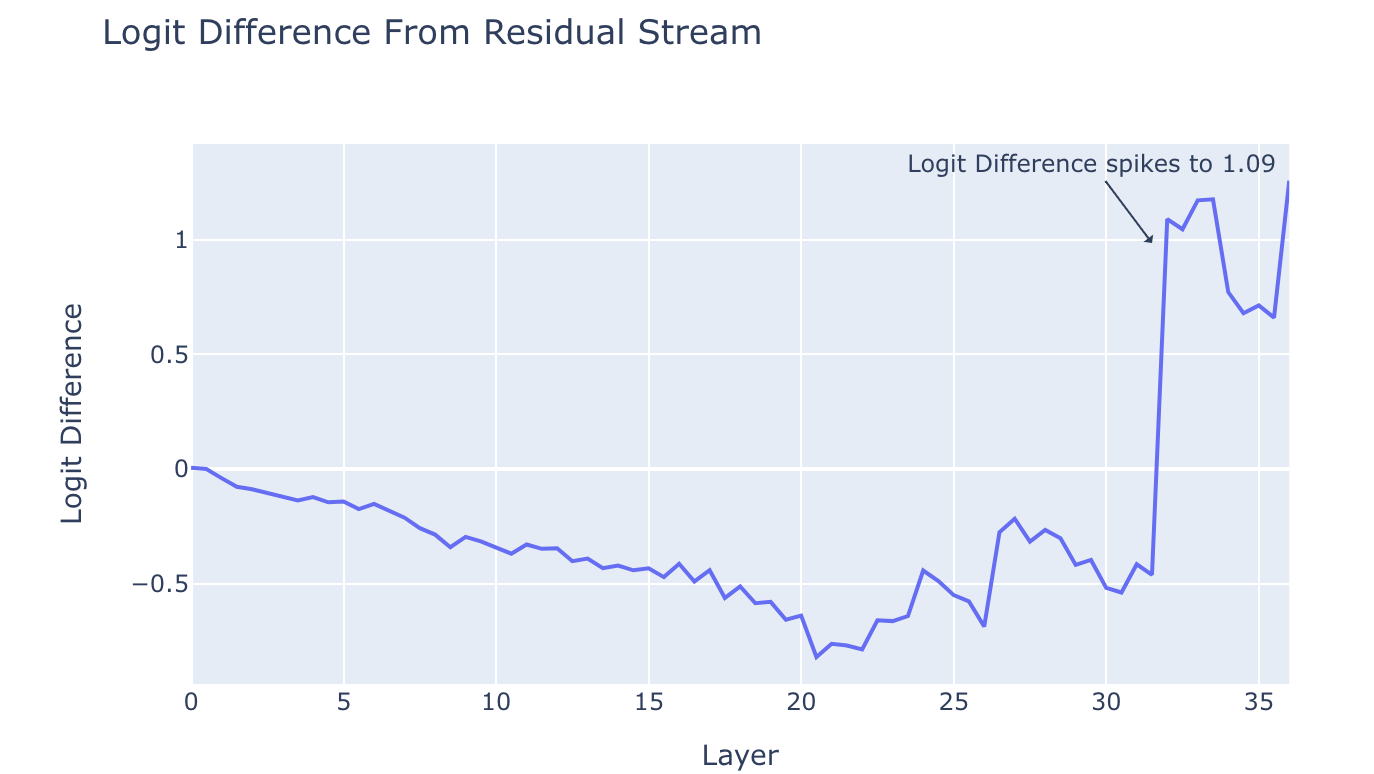
使用 logit 透鏡 這種技巧,我們在模型的每層之間從殘差流中取出 logit,並繪製 logit(“ an”) 和 logit(“ a”) 之間的差異。我們在第 31 層的 MLP 之後發現了一個大的峰值,如下圖。
層次激發修補(Activation Patching by the Layer)
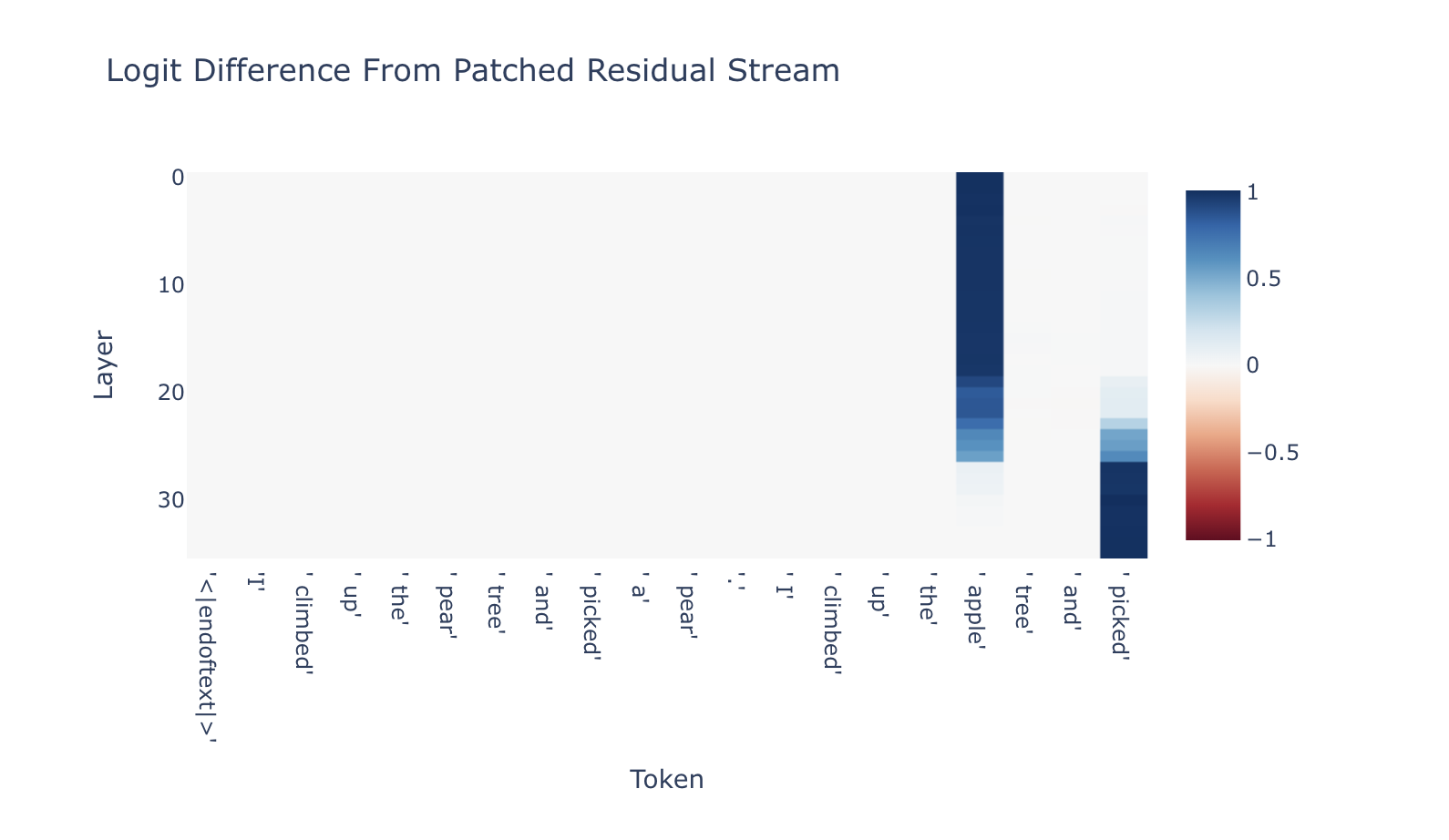
激發修補是一種由 Meng 等人 (2022) 提出的技術,用於分析 Transformer 中單層的重要性。在這個技術中,我們會先將一開始提到的提示運行於模型時,然後我們會將每一層的激發保存起來又稱“淨激發(clean activation)”。
接著,我們將提示詞中蘋果樹(apple tree)改成檸檬樹(lemon tree)並丟給模型:
“I climbed up the pear tree and picked a pear. I climbed up the
appletree and picked”
“I climbed up the pear tree and picked a pear. I climbed up the
lemontree and picked”
通過將 “apple” 替換為 “lemon”,我們誘使模型預測 “ a” 而非 “ an”。當模型預測 “ a” 而非 “ an” 時,我們可以將當前這層中的激活替換為其淨激活,以查看模型朝向 “ an” token移動的程度,這可以代表該前層對於預測 “ an” 的重要性。我們對模型中的所有層重複這個過程。
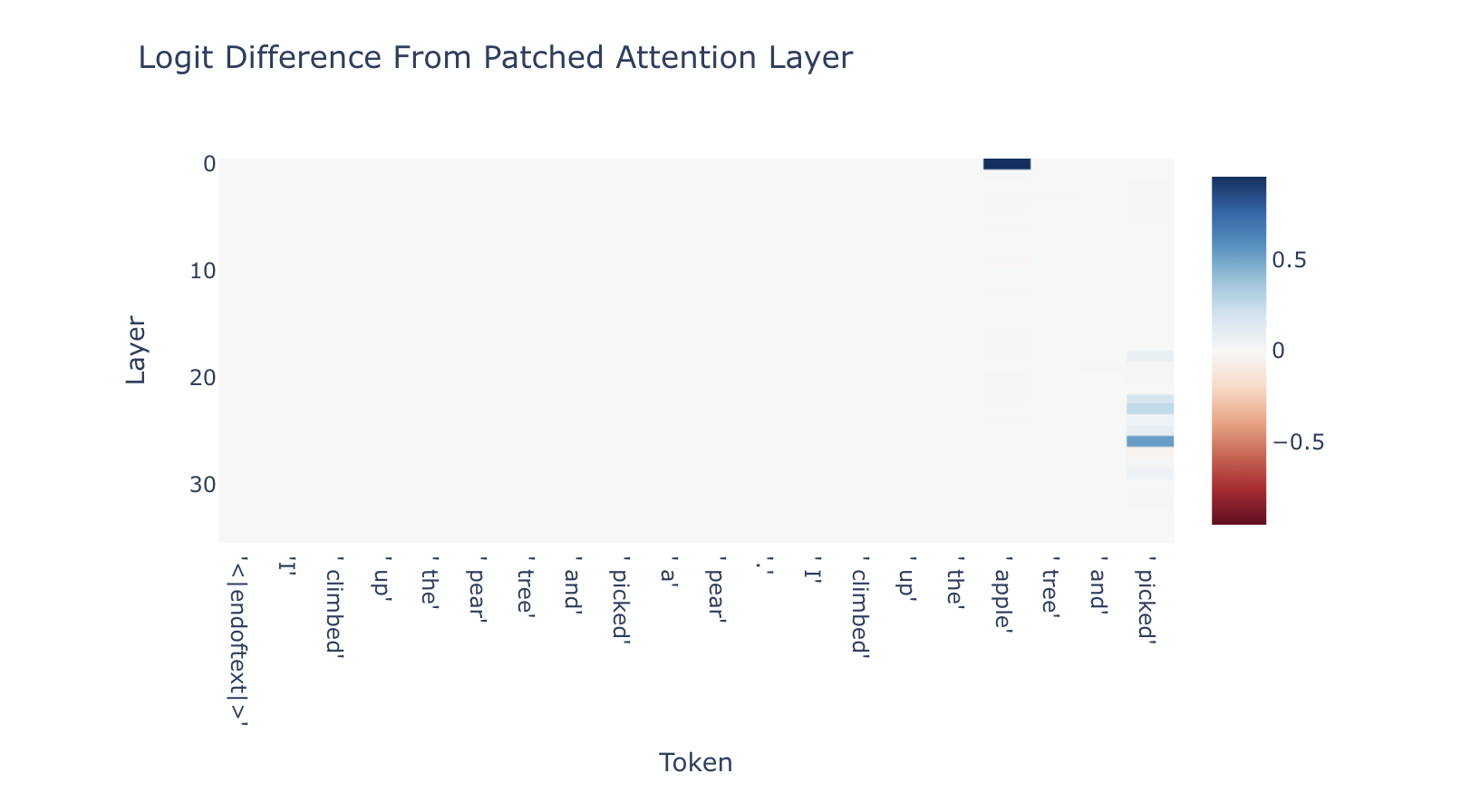
這篇文章接下來我們不會談太多關於 Attention layer 的部分,但這些結果表明,第 26 層是 “ picked” 開始大量考慮 “ apple” 的地方,這顯然是預測 “ an” 所必需要具備的。
注意:圖表上的刻度是相對的邏輯差異恢復程度(relative logit difference recovery)
(也就是說,圖代表有多少修補恢復原先提示中” an”和” a”之間的 logit 比例)
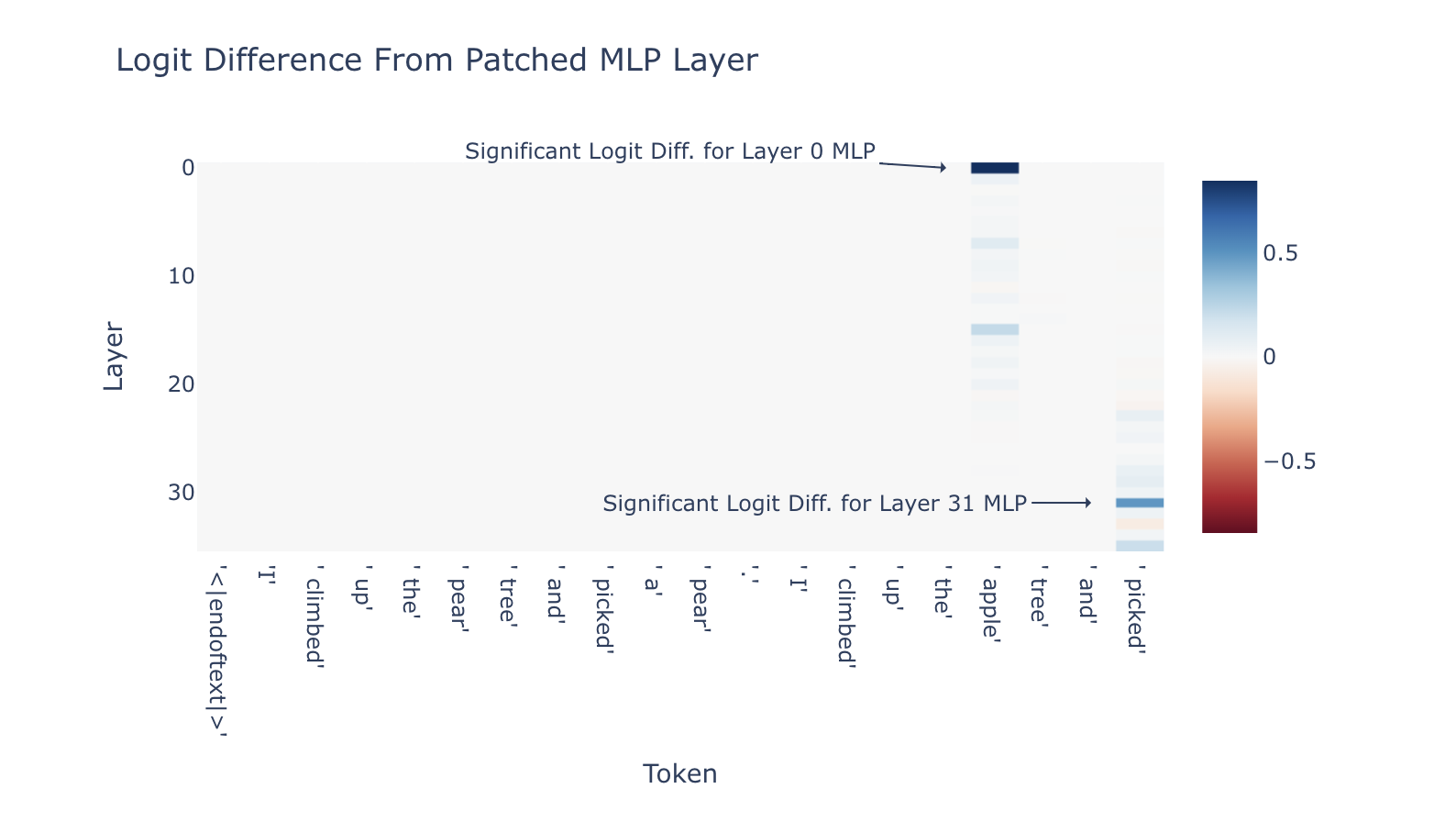
兩個最突出的 MLP 層是第 0 層和第 31 層。我們已經知道第 0 層的 MLP 對於 GPT-2 的運作非常重要(儘管我們不確定為什麼第 0 層的注意力很重要)[註1]。第 31 層的效果更有趣。我們的結果表明,第 31 層的 MLP 在預測 “ an” token 方面有著顯著的作用。(如果你對此結果如何與上面的 logit 透鏡協作感到困惑,你可以參考此處評論 )
發現一:
我們可以通過對單個神經元進行激發修補(activation patching)來發現具有預測性的神經元
激發修補(activation patching)已被用來按層研究 Transformer ,但我們能否將這種技術推向更遠,將其應用到單個神經元?由於 Transformer 中的每個 MLP 只有一個隱藏層,因此每個神經元的激活都不會影響 MLP 中的其他神經元。所以,我們應該能夠對單個神經元進行修補,因為它們在同一層的 Attention heads 之間是相互獨立的。
我們以與上述提到的分層修補中類似的方法對第 31 層 MLP 的神經元進行神經元級別的激發修補(activation patching)。當我們將被修改過的提示運行於模型時,在 MLP 中重新引入每個神經元的淨激發(clean activation),並觀察恢復每個神經元對 “ a” 和 “ an” 之間 logit 差異的貢獻。
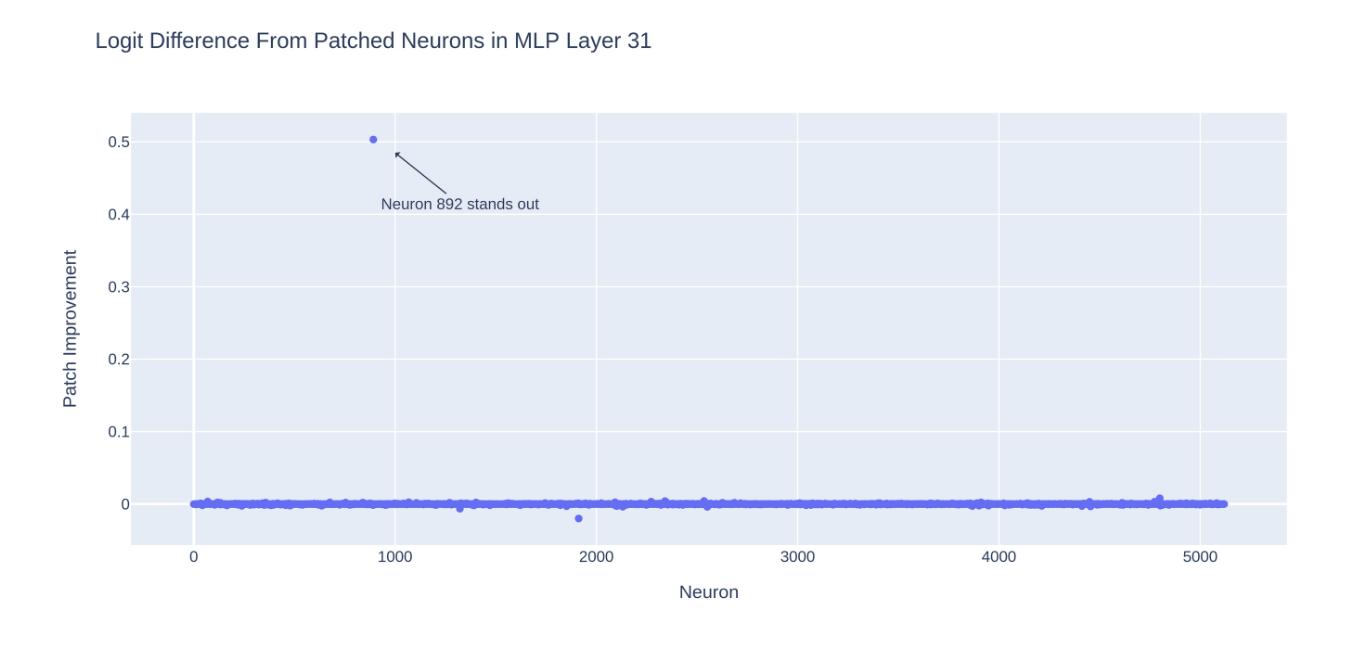
我們可以發現修補神經元 892 可以恢復最初提示中 50% 的 logit 差異,而修補整個層實際上只恢復了 49% 的表現上更差。
總之,我們在 GPT-2 Large 中找到了一個對預測 “ an” token 至關重要的單個 MLP 神經元。通過啟動修補技術,我們可以繼續研究變換器中單個神經元的重要性,進一步了解它們在預測特定 token 方面的作用。雖然我們尚未完全解答開篇提出的問題,但這些發現將有助於我們更深入地理解語言模型的運作機制。
發現二:「an-神經元」的激發與「an」token 預測相關性
Neuroscope 第31層的892號神經元 最大激發案例

Neuroscope 是用來查看 GPT-2 中每個神經元在大型資料集中最大激發案例的線上工具。當我們觀察第31層,編號892神經元時,我們發現這個神經元在後續 token 是「an」的情況下達到最大的激發(maximally activates)。
但 Neuroscope 只顯示出最高激發的前 20 個範例。我們想知道的是在更廣泛的激發範圍內,神經元與 token 是否存在相關性?
在更大的數據集上測試神經元
為了確認這一點,我們將 pile-10k 資料集運行在模型中。這是一個多樣化的資料集,包含了大約 1000 萬個來自 The Pile 的標記,分成 1024 個標記的提示。我們繪製了神經元激活範圍內「an」預測的比例:
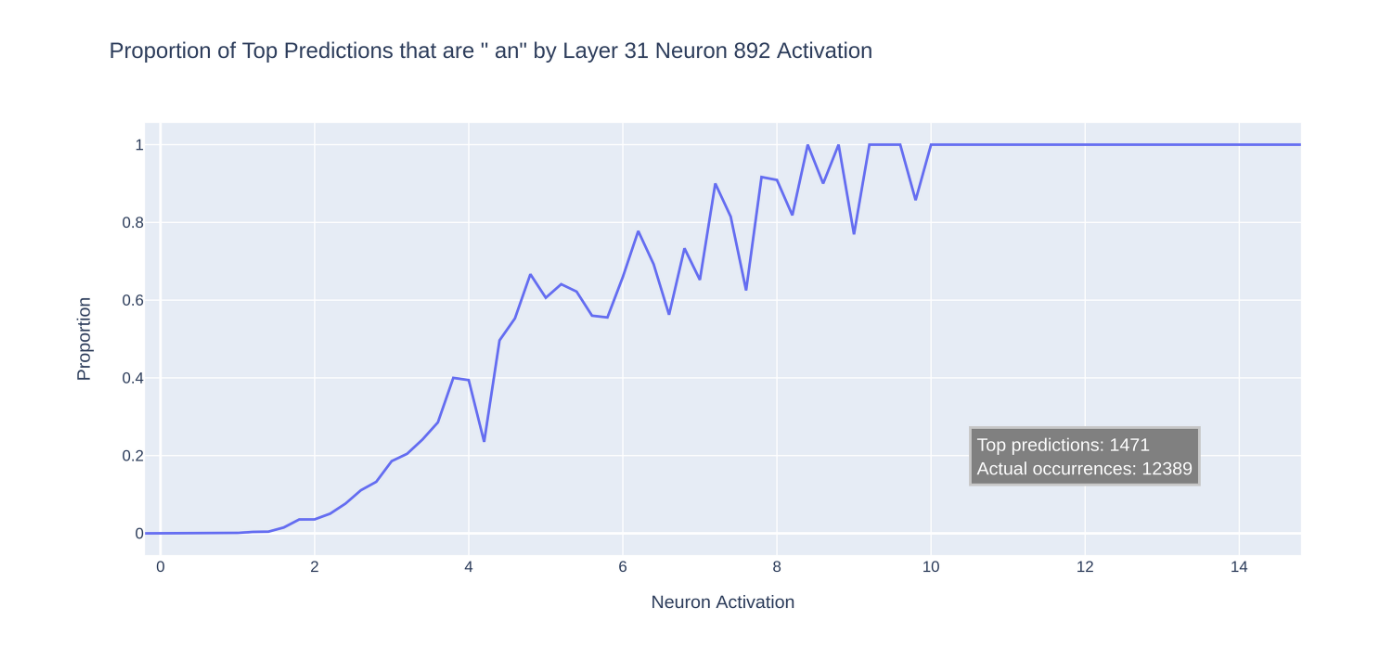
我們看到「an」 token 的預測率隨著神經元激發數增加而增加,甚至到達總是最高預測的程度。趨勢中可以看出有些噪聲,這暗示模型中可能還有其他機制也對「an」的預測有所影響。或者當「an」的 logit 增加時,其他 logit 也會同時增加。
值得注意的是,儘管資料集中實際出現了 12,000 次「an」,但模型只預測了 1,500 次「an」。難怪找到一個好的提示這麼困難!
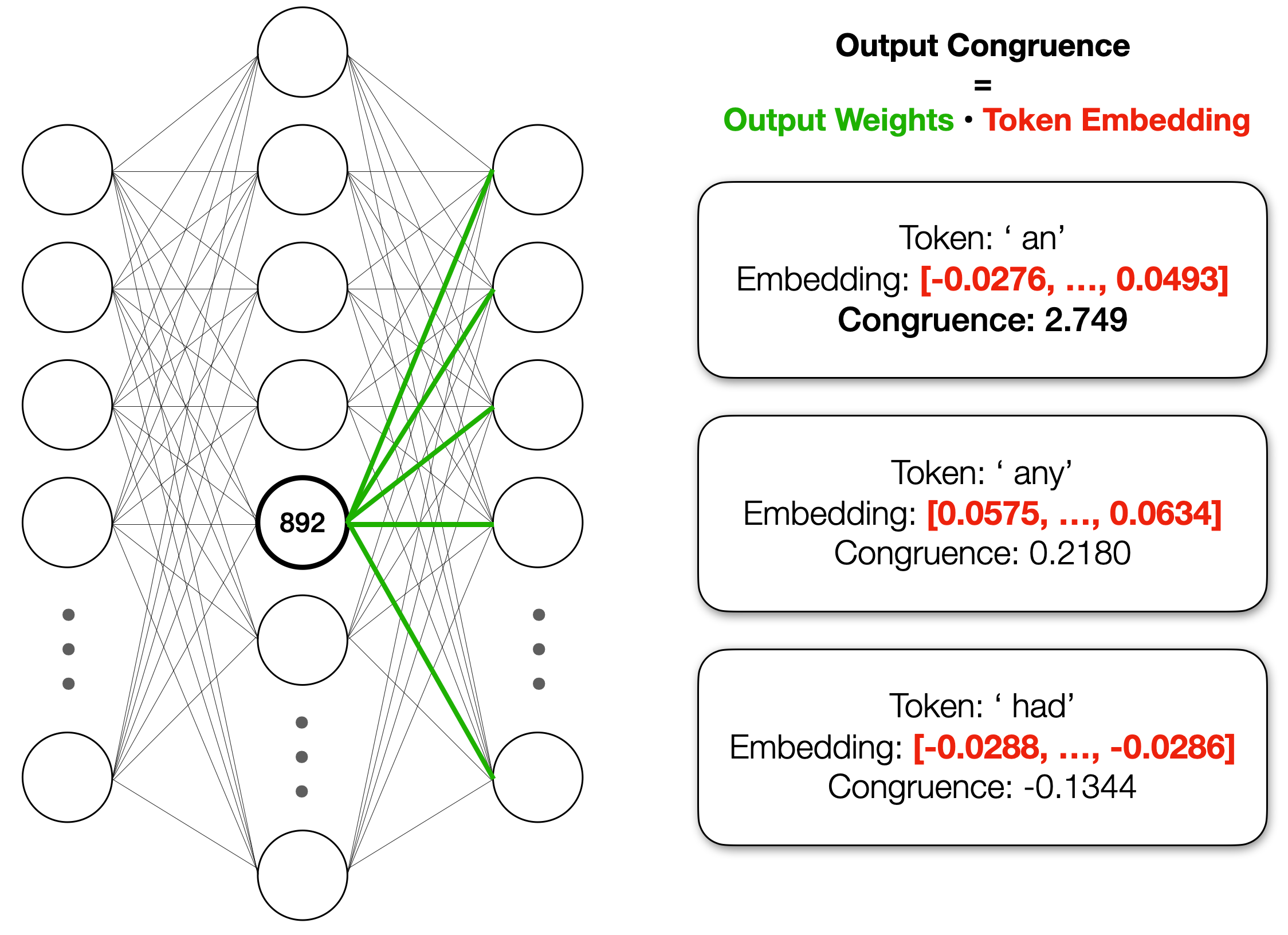
神經元的輸出權重(output weights)與「an」token 的內積很高
神經元如何影響模型的輸出?有趣的是,神經元的輸出權重與「an」token 的嵌入有很高的內積。我們將這個內積稱為這個神經元與 token 的一致性(congruence)。與其他token相比(如「any」和「had」),神經元的一致性在「an」這個token中表現的非常高:
事實上,當我們計算神經元與所有 token 的一致性(congruence)時,有一些明顯的異常值:
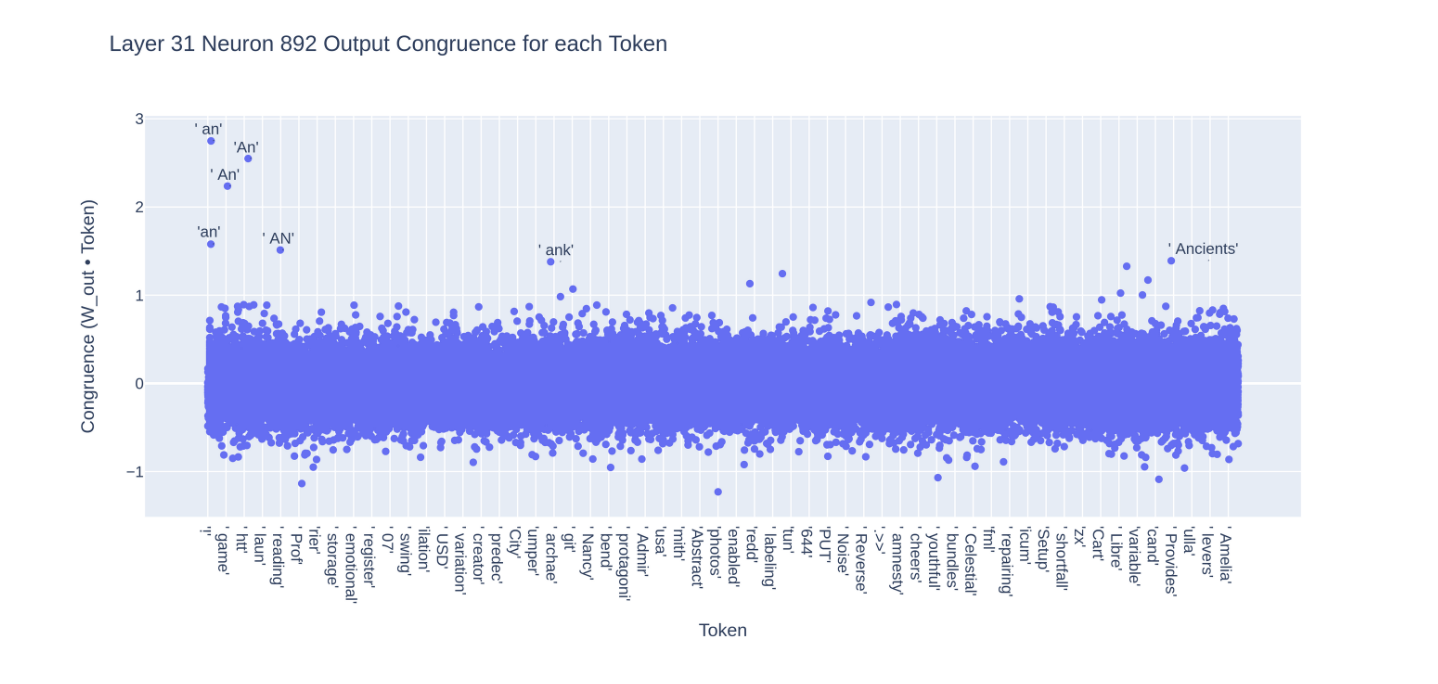
看起來這個神經元基本上是將「an」的嵌入添加到殘差流(residual stream)中,這增加了「an」的輸出機率,因為移除嵌入的步驟包括將最終殘差與每個token的內積相乘。[註2]
還有其他神經元也與「an」一致嗎?為了找出答案,我們繪製了所有神經元與「an」標記的一致性圖: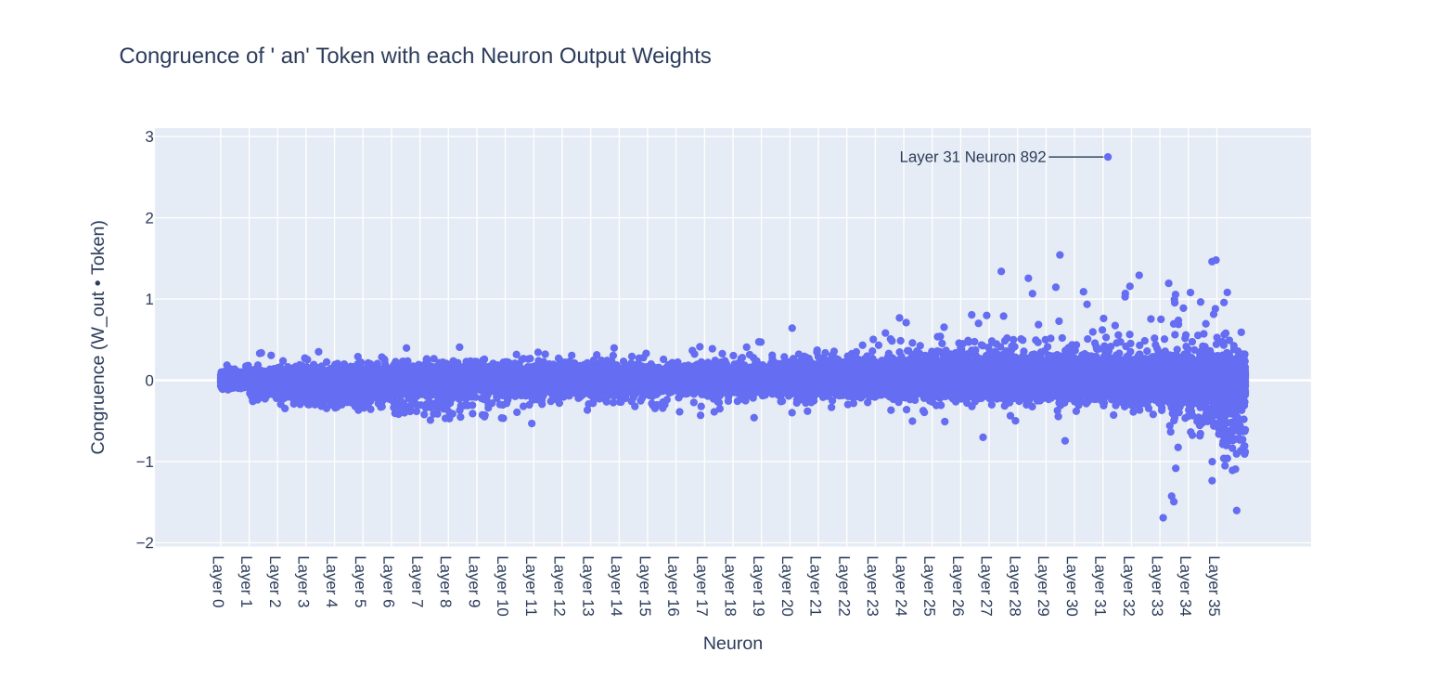
我們的神經元(31-892)的一致性遠高於其他神經元,但還有一些其他神經元具有相當高的一致性(congruence)。這些其他神經元可能是為什麼「an」神經元激發時與「an」token 預測之間相關性不完美的原因之一:有可能存在其他提示(prompt)有著「an」,而模型是使用其他神經元來完成該提示的「an」token。
如果是這樣的話,我們能否使用一致性來找到與單個 token 預測有完美相關性的神經元?
發現三:我們可以使用神經元的輸出一致性來找到預測 token 的特定神經元
找到與特定 token 相關的神經元
我們可以透過以下步驟搜索來找到與特定 token 相關的神經元:
- 對於每個 token,找到具有最高輸出一致性(congruence)的神經元
- 對於這其中的每一個神經元,比較預測同一個 token 中擁有最高一致性和第二高的神經元
- 找到擁有 最獨特一致性(the most exclusively congruent)的神經元。
通過這種搜索,我們希望找到對特殊 token 具有影響力的神經元。我們的猜想是,這些神經元的激發與其 token 的預測更相關,因為該 token 的任何預測都會「依賴」於該神經元。
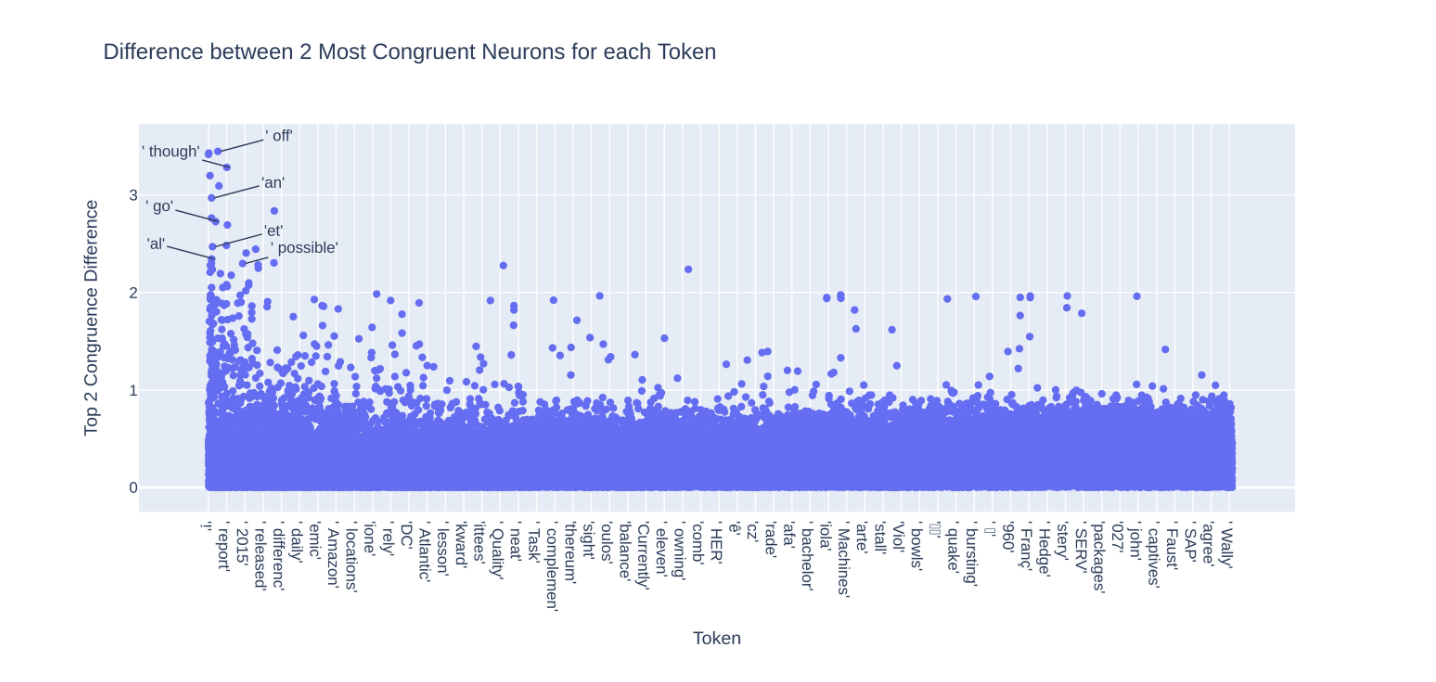
讓我們試著跑一次「though」神經元 - 第 28 層神經元 1921 - 看我們是否能得到更乾淨的統計圖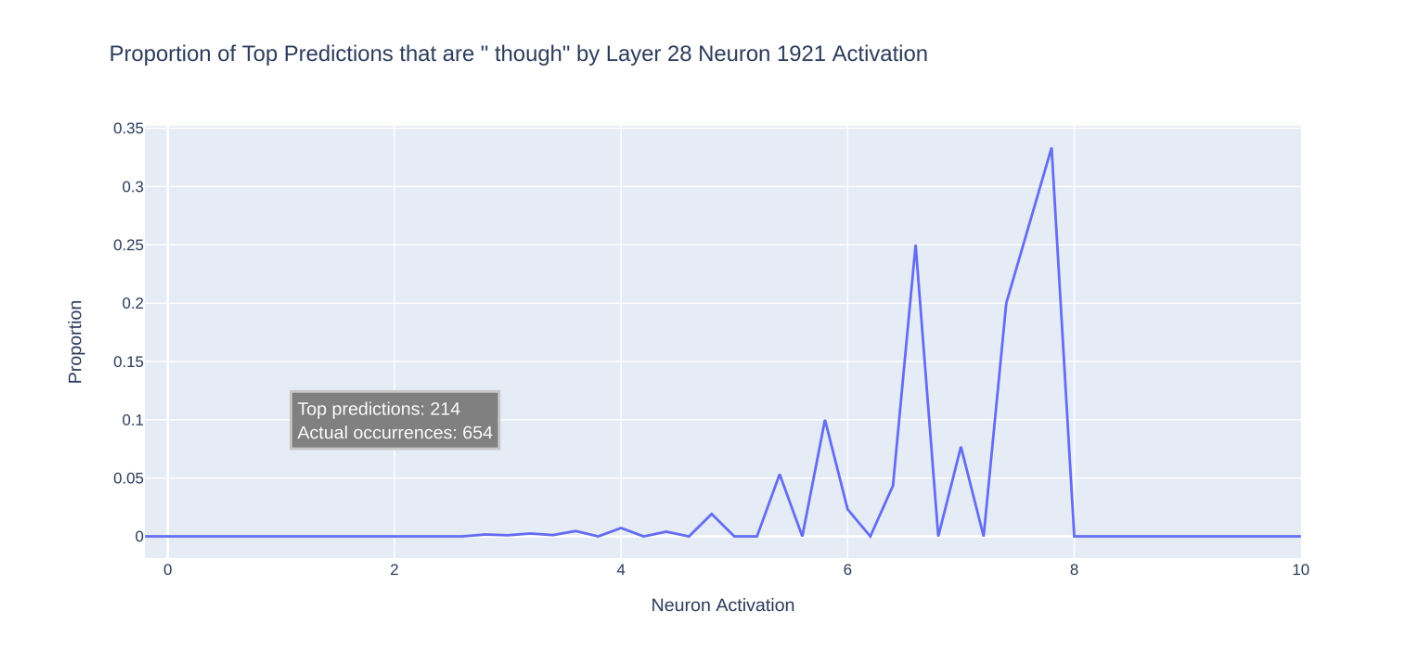
哇,這比” an”神經元的圖要亂多了。發生了什麼事?
我們來看看 Neuroscope 提供的神經元數據,發現這個神經元負責預測了” though”和” however”這兩個token。這讓事情變得更複雜,因為看來這個神經元是與一組語義相似的 token(連接副詞)相關。
[註3]
當我們計算神經元與所有 token 的一致性時,我們發現類似的 token 經常作為異常值出現: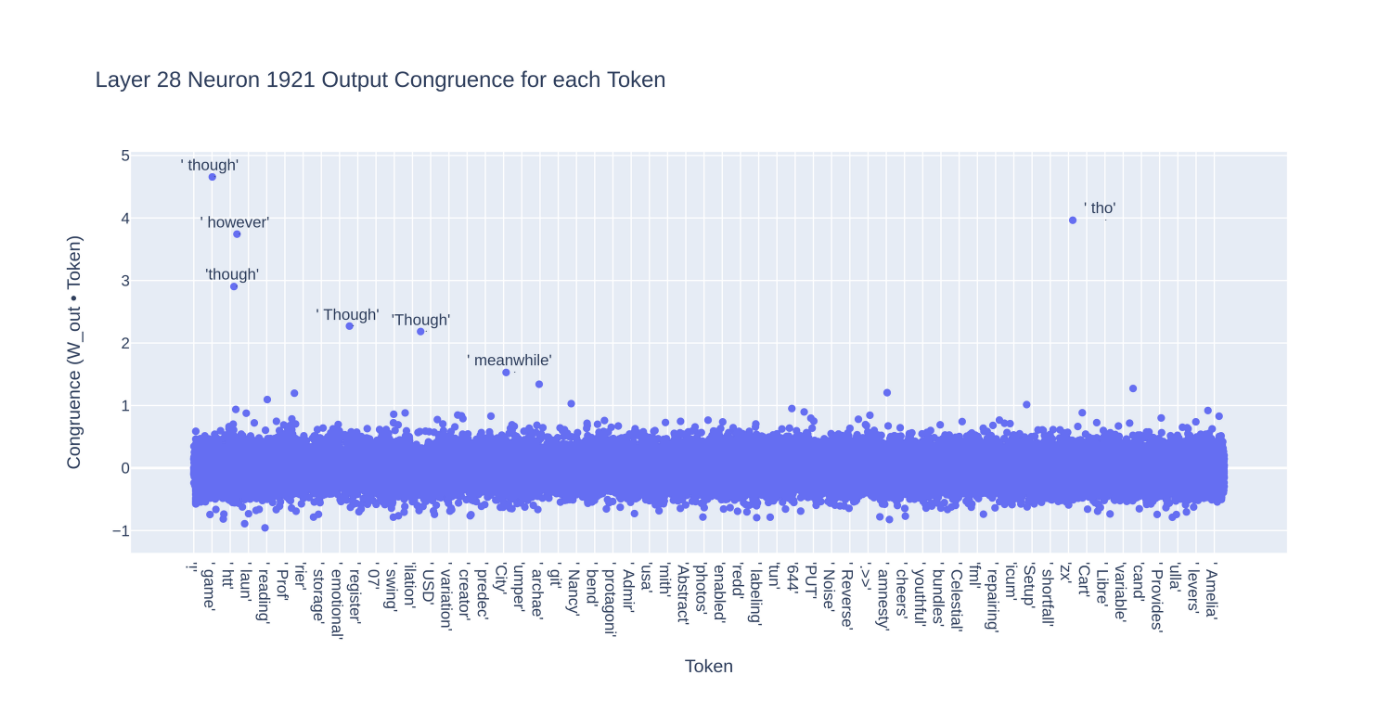
在上面的大型數據集相關圖中,神經元激發並且預測” however”這個 token 的一致性被預測” though” token 超過的狀況是一個負面的案例,因為” though” 不是這個神經元最高預測 token 。這也可以解釋” an”相關中的一些噪聲,因為與”An”、” An”和”an”具有相同的意思,這有可能是噪聲的來源。[註4]
我們能找到一個更簡單的神經元來研究嗎?最好是一個只預測單個 token 的神經元。
找到一個乾淨的關聯神經元
要使神經元與 token “乾淨地關聯”,它們之間的一致性應該是互斥的,這意味著:
- 神經元與token的一致性遠大於與其他任何神經元的一致性。
- 神經元與token的一致性遠大於與其他任何token的一致性。
(請記住,”一致性(congruence)”僅是我們表達內積的術語。)
這兩個標準都有助於簡化神經元與其 token 之間的關係。如果神經元與 token 的一致性是表示神經元對該 token 預測的貢獻程度,第一條規則是確保「只有這個神經元」負責預測該token,而第二個規則則可以確保這個神經元「只會負責預測該token」。
我們的搜索如下:
- 對於每個 token,找到最一致的神經元。
- 對於每個神經元,找到最一致的 token。[註5]
- 找到兩個列表上的token神經元對,即神經元最一致的token是與該神經元最一致的token!
- 通過將它們的前兩個token一致性差與前兩個神經元一致性差相乘,計算它們之間的差異程度。
- 找到具有最高互斥一致性的對。
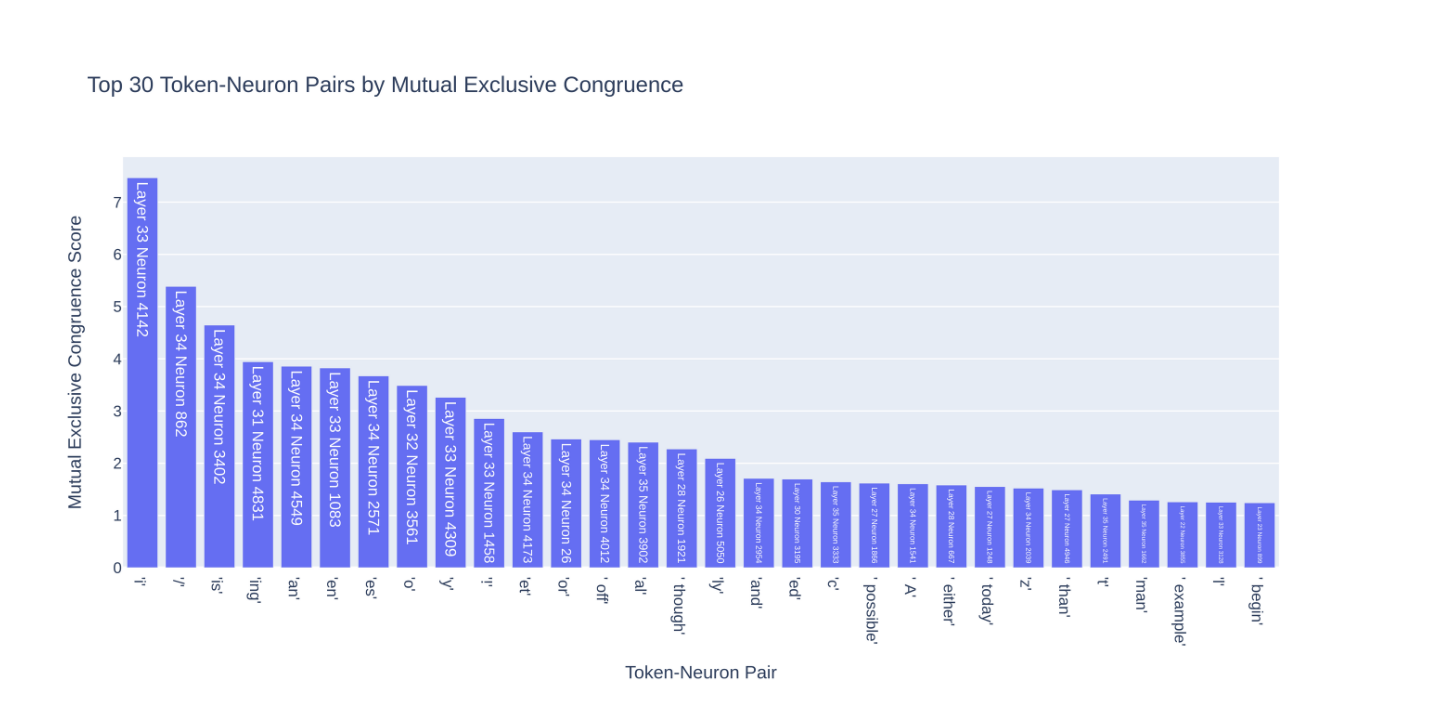
對於GPT-2_large,第33層神經元4142與”i”配對在這個度量上得分最高。查看 Neuroscope [註6]確認了這個關聯:

當我們繪製前5名最高得分者的最高預測比例與激發圖時:[註7]
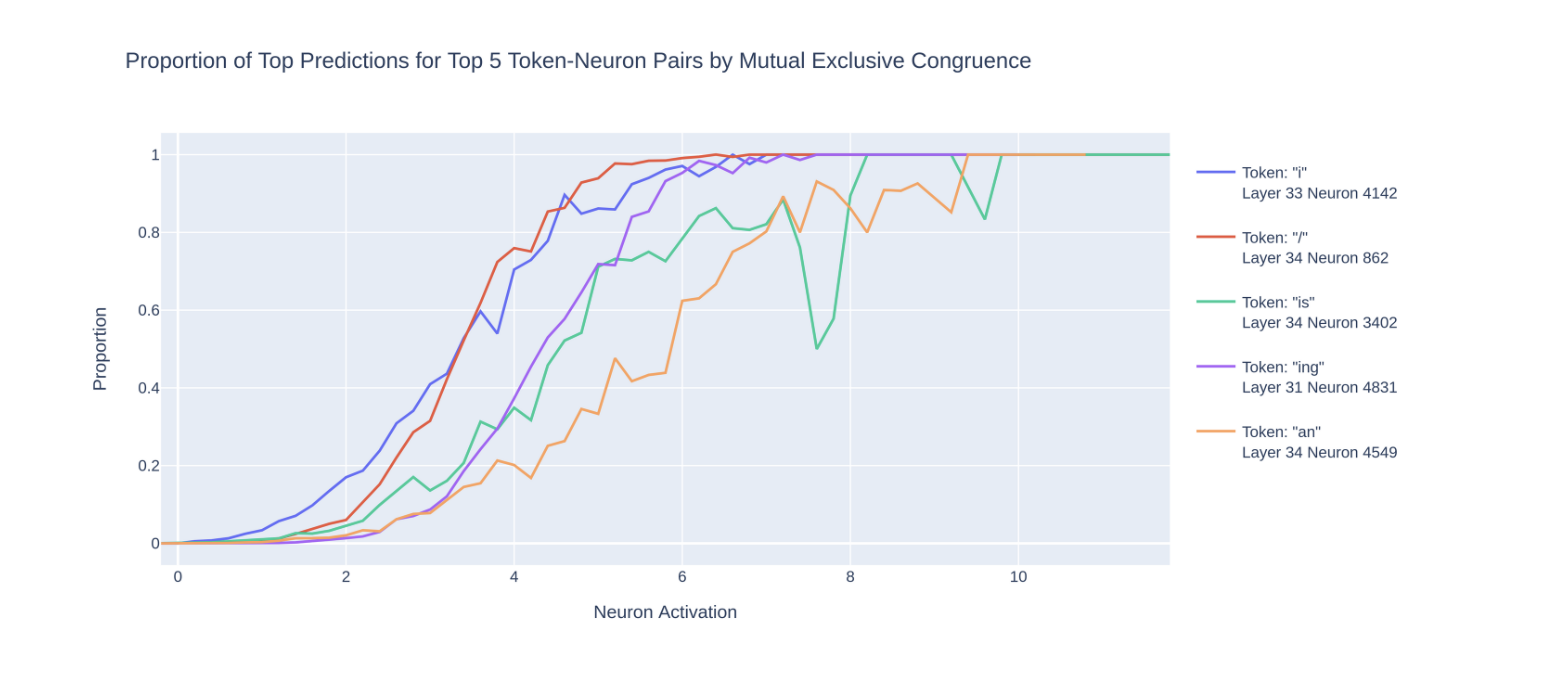
我們確實看到了每對之間的強相關性!
這一切意味著什麼?
神經元與token的一致性是否真的衡量了神經元預測該token的程度?我們不知道。即使具有高互斥一致性的token神經元對也可能並不總是具有相關性,原因可能有幾個:
- token也可能由一組一致性較低的神經元共同預測。
- token可能由注意力頭(attention heads)預測。
- 即使神經元的激發與 token 的 logit 具有高度相關性,它也可能間接地與其他 token 的 logit 相關,以至於神經元的激發與 token 出現的機率不具有相關性。
- 可能有後續層往殘差流中添加相反方向,從而抵消神經元的效果。
雖然是這樣說,但我們發現具有最高互斥一致性的前5名的神經元確實對上 token 預測具有很強的相關性。
TL; DR
- 我們在神經元級別上使用激發修補(activation patching)找到了一個對於預測特定提示中的token “ an”非常重要的神經元。
- “ an”神經元的激發與” an” token 的預測有一般相關性。
- 這可能是因為神經元的輸出權重與” an” token具有很高的內積(神經元與 token 有高度一致性)。此外,這個神經元與這個 token 的內積比其他任何 token 都要高。而且,這個 token 與這個神經元的內積比 token 與其他任何神經元的內積都要高(它們具有高度互斥的一致性)。
- 神經元與 token 之間的一致性很酷。我們找到了前5名具有互斥一致性的 神經元-token 對。這些神經元的激發與它們各自的 token 預測密切相關。
重現我們結果的程式碼:https://github.com/UFO-101/an-neuron
這是我們在Apart Research 的黑客松 中獲勝所提交的文章做的延伸。感謝倫敦EA Hub 讓我們使用他們的共享工作空間,感謝Fazl Barez的評論 和 Neel Nanda的建議 ,以及 Neuroscope 、pile-10k資料集 和TransformerLens 。
註解
[註1]
Neel Nanda 對 MLP 第0層的看法:
“通常在GPT-2 Small上觀察到,MLP 第0層非常重要,抑制它會徹底破壞LLM的性能。我目前最好的猜測是,第一個MLP層基本上是 prompt 嵌入的擴展(無論出於什麼原因),當後續層想要訪問輸入 token 時,它們主要讀取的是第一個 ML 層的輸出,而不是 prompt。在這個框架下,第一個注意力層幾乎沒有什麼作用。
在這個框架下,MLP 第0層在第二個主題 token 上很重要,因為這是唯一一個位置有不同的輸入 token!
我不完全確定為什麼會這樣,但我的猜測是,這是因為在GPT-2 Small中,嵌入和去嵌入矩陣是相同的。這是相當不合理的,因為嵌入和去嵌入token的任務並不是互逆的,但這是常見的做法,模型可能希望將一些參數用於克服這一點。
我只有暗示性的證據,希望有人能夠好好研究這個問題”
[註2]
神經元還有哪些可能的作用?它可能抑制了” a”的 logit,這對 logit 差異會產生相同的影響。或者它可能向殘差流中添加了完全不同的方向,導致後續層的神經元增加了” an” logit。
[註3]
值得注意的是,” though”神經元與一組語義相似的token一致,而” an”神經元與一組語法相似的token相關(例如,” an”和” Ancients”)。
[註4]
為什麼” an”具有更乾淨的相關性,儘管有其他一致的token(“an”, “An”, “ An”)?我們不能確定。一個可能的解釋是,”An”和” An”只是非常不常見的 token,所以它們對對相關性的影響很小,而”an”與此神經元的一致性遠低於其他三者。
一般來說,我們只查看每個token的前2名神經元差異來找到的神經元,通常不會與其相對應的token具有乾淨的相關性,因為這些神經元可能同時與多個token有一致關係。
[註5]
當我們觀察每個token的最一致神經元時,我們可以看到了一些非常高一致性的熟悉的麻煩製造者 :
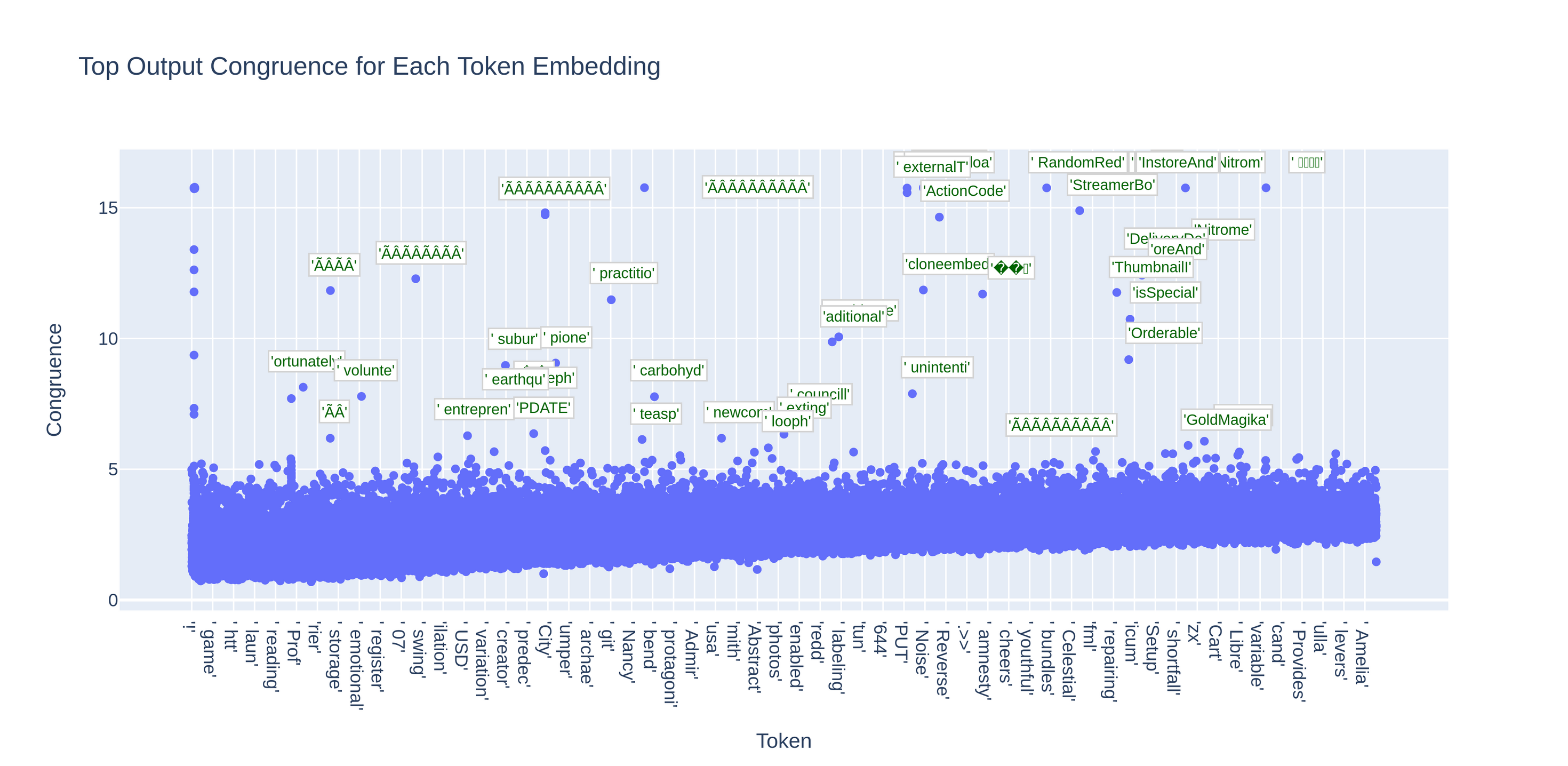
起初,看起來這些”禁止的token”都與一個”禁止的神經元”(第35層神經元3354)相關,它們都與該神經元非常一致。但實際上,如果我們繪製許多其他神經元的最一致token,我們也會看到一些這樣的奇怪token位於排名靠前的位置。我們的初步假設是,這可能與hubness effect(集束效應) 有關。
[註6]
Neuroscope 數據對於這個神經元並不可用,所以我們從 pile-10k 資料集中選擇了最大激發數據集案例。文本1、2、3分別是提示1755、8528和6375。
[註7]
值得注意的是,前5個token之一是”an”,但這與我們之前提到的” an”不同,它很少作為一個單詞的開頭或單獨使用的單詞。同樣,與之配對的神經元,第34層神經元4549,也不是前面提到的” an”神經元。
- Title: 類神經網路中神經元對特定單字的預測
- Author: Zero6992
- Created at : 2023-04-17 00:19:00
- Updated at : 2023-08-24 06:01:33
- Link: https://zero6992.me/2023/04/17/gpt2-predicted-token/
- License: This work is licensed under CC BY-NC-SA 4.0.